研修効果を最大化するために考えておきたいポイント
データサイエンスの一部として話題になるAI(人工知能)や機械学習、そしてIoTといった最新技術の言葉があります。
企業のビジネスに応用して使うとどうなるのだろうか?
と考える人は少なくありません。
さすがに最近では少なくなってきた感じがあるものの、これら最新の「データサイエンス」技術を導入することと、実務の現場で「データ分析を活用する」こととの区別がしっかりできていないまま、中途半端な状態でいる組織も少なくありません。
これは、こんなにも目的や内容が異なるものを「データ分析」や「データ活用」といった一般語で一緒くたに論じてしまうことの弊害の一部とも言えます。
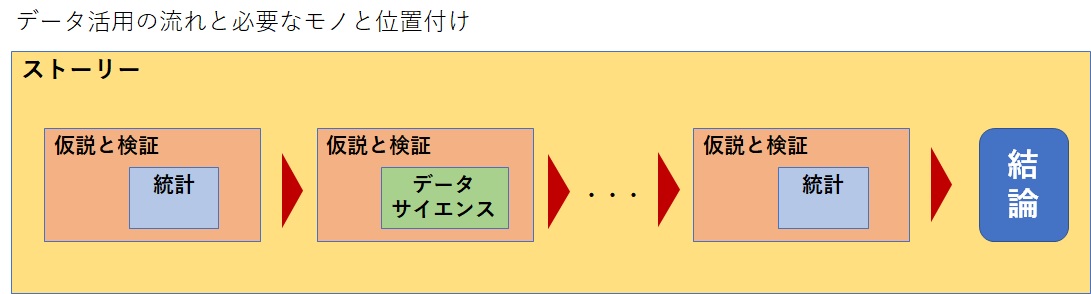
そこで、私なりに、これらを整理してみました。

この図の通り、データ分析の専門家(専門部署)として、最新技術をビジネスに導入することと、実務担当者が自分の戦略を描いたり、問題解決をしたりすることとは全く別ものであることがお分かりいただけると思います。
よく「基礎的なデータ分析スキルを身に付けたら、次のレベルを・・・・」と期待される方がいますが、基礎的なデータ分析スキルの次のレベルは、データサイエンスではありません。
次のレベル(段階・ステップ)とは、基礎的なスキルを自業務に応用して、トライアンドエラーから、場数と経験値を積むことなのです。それは、あくまで「データ分析の実務活用」の範囲であって、決してデータサイエンスのカテゴリーではありません。
組織内でのデータ活用スキルを向上、定着させたいとお考えの方は、一体どちらの話をしているのか、どこを目指したいのかを明確にされると良いと思います。
その際に、上記の図をご参考にして頂ければ幸いです。
データサイエンスは、技術とサイエンスの話です。個人のスキルとは別ものです。
敢えて個人のスキルと組み合わせれば、最新技術の理論の習得と高度なプログラミング技術の習得ということになります。それは、従業員全員が必要とするスキルではありません。
もちろん、私自身はこの図の中の下2段のサポートに特化しています。